Epoch 4: Makemore, Part 1
Intro
Hi, I’m Mon, and here is Epoch 4, Makemore Part 1.
Makemore is a character-level language model, where each character is a token.
The model is trained on a dataset of names and learns to predict the next token (character), allowing it to generate new names that sound realistic.
Step 1: Setup:
Setup the virtual environment, and run the jupyter notebook
mkdir makemore_tutorial
cd makemore_tutorial
python3 -m venv venv
source venv/bin/activate
pip install jupyter
jupyter notebook
And make a new notebook: makemore
Clone the Karpathy’s Makemore repo
Copy “names.txt” to the makemore_tutorial directory.
Content: Bigram Part 1
Let’s begin with making a bigram
Bigram: Given the previous character, what is the next character likely to be?
import the numbers list:
words = open('names.txt', 'r').read().splitlines()
words[:10] #check the words
['emma',
'olivia',
'ava',
'isabella',
'sophia',
'charlotte',
'mia',
'amelia',
'harper',
'evelyn']
We need to find a way to store all the sequence of characters’ transitions, one input, one output, for all names,
i.e. “e m”, “m m”, “m a” …
for w in words:
for ch1, ch2 in zip(w, w[1:]):
print(ch1, ch2)
e.g. emma -> zip(“emma”,“mma”)
(’e’,’m’), (’m’,’m’), (’m’,‘a’)
inner loop 1: e m
inner lopp 2: m m
inner loop 3: m a
Let’s add starting and ending characters to all names, so we can add find the sequence of starting and ending with characters too.
for w in words:
chs = ['<S>'] + list(w) + ['<E>']
for ch1, ch2 in zip(chs, chs[1:]):
print(ch1, ch2)
# <S> e
# e m
# m m
# m a
# a <E>
# <S> o
Now we need to count the bigram of characters, to do so, we make an empty dictionary. While we loop, we check if the bigram exists, if yes return the count + 1 for that bigram, if not, store the bigram with 0
d = {}
for w in words:
chs = ['<S>'] + list(w) + ['<E>']
for ch1, ch2 in zip(chs, chs[1:]):
bigram = (ch1, ch2)
d[bigram] = d.get(bigram, 0) + 1
d
#{('<S>', 'e'): 1531,
# ('e', 'm'): 769,
# ('m', 'm'): 168,
# ('m', 'a'): 2590,
# ('a', '<E>'): 6640,
#...
Now sort by
sorted(d.items(), key = lambda kv: -kv[1])
#[(('n', '<E>'), 6763),
# (('a', '<E>'), 6640),
# (('a', 'n'), 5438),
# (('<S>', 'a'), 4410),
#...
Note 1:
d.items() converts dictionary d into a sequence of (key, value) tuples, so each dictionary entry k1: v1 becomes the tuple (k1, v1)
Content: Bigram Part 2
Let’s use tensors for our dictionary
28 row in 28 column, think like multiplication table, to store all the bigram combinations in 1 tensor
import torch
N = torch.zeros((28, 28), dtype=torch.int32)
26 english letters + 1 begin + 1 end
Now we store all the characters by:
1. join all words together
2. use set() to remove the duplicate characters, so we get all the 26 characters
3. use list() to make a list
4. sort characters with sorted()
allwords = ''.join(words)
chars = sorted(list(set(allwords)))
charts
# ['a',
# 'b',
# 'c',
# 'd',
# 'e',
# ...
# ]
Now let’s give characters, ordered number, which represents their location in tensor.
stoi = {s:i for i,s in enumerate(chars)}
stoi['<S>'] = 26
stoi['<E>'] = 27
stoi
# {'a': 0,
# 'b': 1,
# 'c': 2,
# 'd': 3,
# ...
# }
Next is to implement the tensor mapping in our loop
for w in words:
chs = ['<S>'] + list(w) + ['<E>']
for ch1, ch2 in zip(chs, chs[1:]):
ix1 = stoi[ch1]
ix2 = stoi[ch2]
N[ix1,ix2] += 1
N
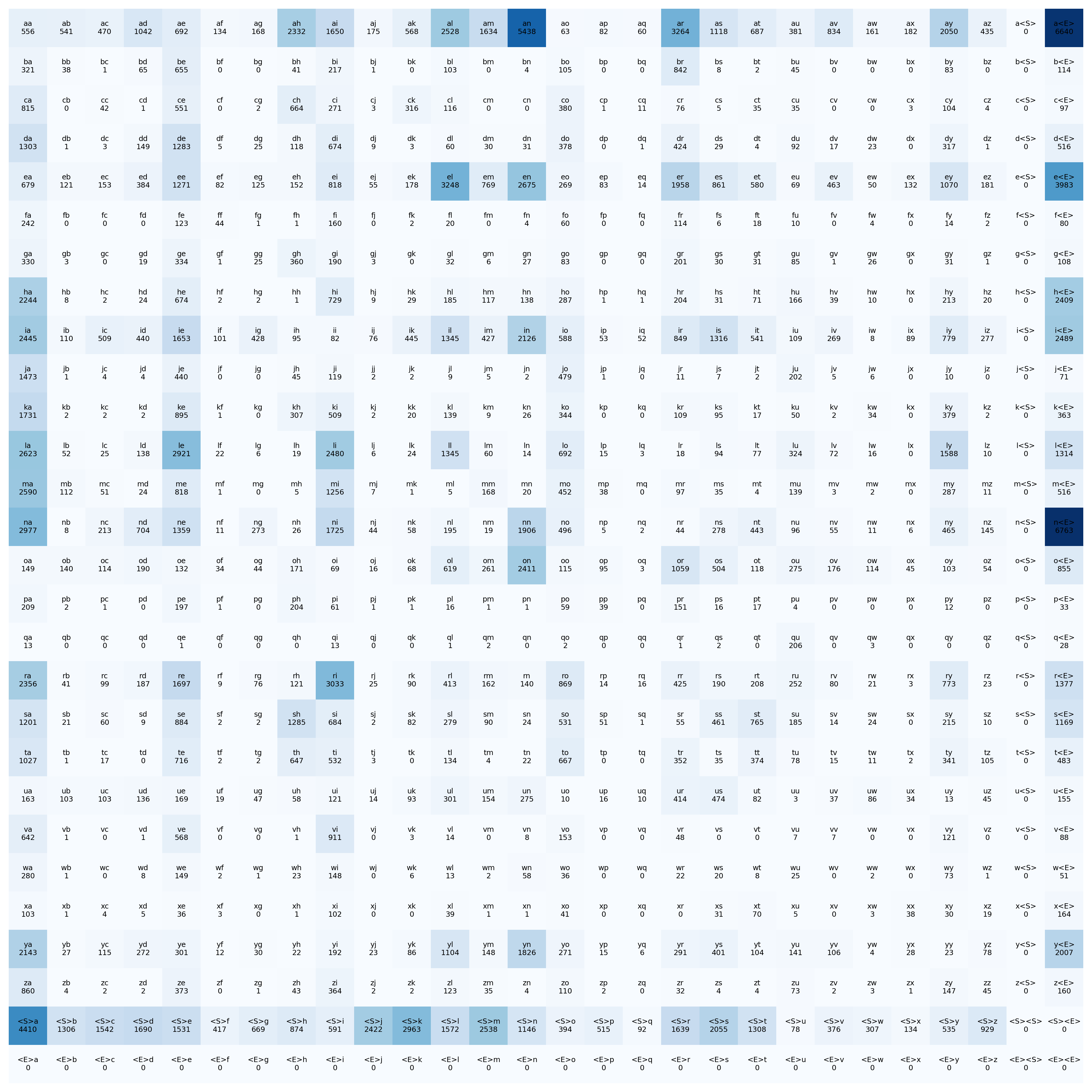
–> Make plot of the tensor
import matplotlib.pyplot as plt #1
%matplotlib inline #2
plt.figure(figsize=(16,16)) #4
plt.imshow(N, cmap='Blues') #5
for i in range(28):
for j in range(28):
plt.text(j, i, f"{chars[i]}{chars[j]}\n{N[i,j].item()}", #9
ha='center', va='center', fontsize=6)
plt.axis('off')
plt.show()
line 1 imports plot lib
line 2 jupyter notebook command to say plot inside the current window
line 4 canvas size
line 5 imshow, shows the colormap of tensor, imshow internally does linear scalar mapping for the color map
it finds max: darkest color and min: lightest color of the numbers, then it normalize all the other numbers with:
$$ \text{normalized value} = \frac{N[i,j] - N_{\min}}{N_{\max} - N_{\min}} $$
line 7 loops over all i, and j
line 9 note: x: j , y: i , it finds the cell in the tensor, then it prints the ij, and with N[i,j].item() it prints the value of the tensor
Content: Bigram Part 3: Sampling, probability distribution
Now let’s create a probability distribution for each row, so we can determine the likelihood of the next character.
Each row represents how many times each character follows a given character.
For example, row 0 (corresponding to ‘a’) might show: ‘aa’: 1000, ‘ab’: …, ‘ac’: … and so on.
If we make our name generator now, we can make it deterministic character picker based on the probabilities distribution (weights), but we need to add creativity and non deterministic way of picking the next character,
So Instead of deterministically choosing the highest-probability character, we perform probabilistic sampling: each selection is influenced by the distribution’s weights but allows variability. Over repeated selections, the resulting frequencies approximate the original distribution, so the weights govern the process on average rather than exactly each time.
dist = N[0].float() #1
dist /= dist.sum() #2
dist
#tensor([0.0164, 0.0160, 0.0139,...])
line 1 convert tensor values of row 0 to have float decimal
line 2 probability distribution: row 0 is normalized by dividing to the sum of all occurrences to get the probabilty of each values, so the sum of all probs will be 1 (dist.sum() = 1).
Sampling: picking one outcome at random from a probability distribution.
As we said, to add some level of probabilty and creativity, and non deterministic results,
we need to have some randomness,
In here we use manual_seed so our random number can be generated the same (for testing purposes)
–> 1. probability distribution
this is a simple example of probabity distribution from a simple 1D tensor, note that later we can use the probabilty distribution from the tensor we made for the names.
g = torch.Generator().manual_seed(112234234)
p = torch.rand(3, generator = g)
p /= p.sum
p
#tensor([0.3001, 0.2650, 0.4349])
–> 2. sample from prob. dist. with multinomial
input: prob. dist. (index + probabilities)
output(each sample): indice, representing the occurrence of a member in prob. dist.
torch.multinomial(p, num_samples= 100, replacement= true, generator= g)
#tensor([1, 1, 0, 1, 0, 0, 2, 0, 0, 1, 1, 2, 1, 0, 1, 2, 1, 2, 2, 2, 1, 1, 2, 1, 1, 1, 1, 2, 1, 2,...])
replacement=true: It is allowed to use same indices for samples
if replacement is false, the result has no repated indices,
and in this case the num_samples must be equal or less than the p.size(0)
–> 3. use names prob. dist.
Now lets use the prob. dist. we made dist to feed our multinomial to get one sample
sample = torch.multinomial(dist, num_samples= 1, replacement=True, generator=g)
sample.item()
#17
Now we look for the index 17 in our tensor N
itos[ix]
#'u'
so ‘u’ is the next character if we use ‘a’ -> au
Now let’s make a loop, to make names
g = torch.Generator().manual_seed(11224234)
for n in range(10):
out = []
ix = 0
while True:
dist_all = N[ix].float()
dist_all /= dist_all.sum()
ix = torch.multinomial(dist_all, num_samples= 1, replacement=True, generator=g ).item()
out.append(itos[ix])
if ix == 27:
break
print(''.join(out))
#iumolinevamy<E>
#pph<E>
#lw<E>
#rao<E>
#tttee<E>
#llun<E>
#llylelezauerdr<E>
#na<E>
#yars<E>
#ieeni<E>
This loop runs 10 times (generates 10 names)
For Each name:
It generates a new ix everytime (sample of row), it append the character, then it uses the ix as the new multinomial initiator for the next loop,
when it hits <E> index:27,
( it ends this step, it prints out (name),
then it clears out for the new name (next batch of loops)