Epoch 2: Micrograd, Part 2
Intro
Hi! I’m Mon, this is Epoch 2, Micrograd, Part 2, in the previous epoch we learnt how to implement the addition and multiplication and build a tiny engine that can calculate local derivatives and global gradients.
Before jumping to Neural Network (nn), we should implement:
- subtraction (errors, losses)
- powers (squared loss)
- division (normalization, scaling)
- non-linear functions
Content: Completing Operations
Subtraction
$$ c = a - b $$
rewrite: $$ c = a + (-b) $$
Derivatives:
$$ \frac{\partial c}{\partial a} = 1 $$
$$ \frac{\partial c}{\partial b} = -1 $$
means if b increases slightly, c decreases by the same amount
# Subtraction
def __sub__(self, other):
other = other if isinstance(other, Value) else Value(other)
return self + (-other)
Negation
# Negation
def __neg__(self):
out = Value(-self.data, (self,), 'neg')
def _backward():
self.grad += -1 * out.grad
out._backward = _backward
return out
Power
Let:
$$ c = a^n $$
Where:
ais a Valuenis a constant
Derivative:
$$ \frac{\partial c}{\partial a} = n \cdot a^{n-1} $$
For here the exponent is not a Value to
- keep the engine minimal
- avoid unnecessary graph complexity
def __pow__(self, n):
assert isinstance(n, (int, float))
out = Value(self.data ** n, (self,), f'**{n}')
def _backward():
self.grad += n * (self.data ** (n - 1)) * out.grad
out._backward = _backward
return out
Division (by power)
Let:
$$ \frac{a}{b} = a \cdot b^{-1} $$
def __truediv__(self, other):
other = other if isinstance(other, Value) else Value(other)
return self * (other ** -1)
Content: Non-Linearity
- a linear neuron can compute: $z = w_1 x_1 + w_2 x_2 + \cdots + b$
if we add more neurons to make a layer and then a network, still it will be linear.
Linear neurons are not powerful enough!
e.g. computing XOR needs non-linear structure.
So we need to bend the space for them! By adding a non-linear activation (e.g., tanh, sigmoid, ReLU)
Let’s do it with tanh;
Definition:
$$ \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} $$
or
$$ \tanh(x) = \frac{e^{2x} - 1}{e^{2x} + 1} $$
or
$$ \tanh(x) = \frac{y^2 + 1}{y^2 - 1} $$
Range:
$$ -1 < \tanh(x) < 1 $$
We can use the built in tanh in python by using math.tanh(x) or we can go manually write the formula.
Derivative:
$$ \frac{d}{dx} \tanh(x) = 1 - \tanh(x)^2 $$
def tanh(self):
x = self.data
t = (math.exp(2*x) - 1) / (math.exp(2*x) + 1) # careful with parentheses
out = Value(t, (self,), 'tanh')
def _backward():
self.grad += (1 - t ** 2) * out.grad # derivative
out._backward = _backward
return out
Content: Let’s make the graph
1. Install the graph in the notebook
pip install graphviz
and put from graphviz import Digraph in the beginning of the code
2. Code snippet
def trace(root):
nodes, edges = set(), set()
def build(v):
if v not in nodes:
nodes.add(v)
for child in v._prev:
edges.add((child, v))
build(child)
build(root)
return nodes, edges
def draw_dot(root):
dot = Digraph(format="svg", graph_attr={"rankdir": "LR"})
nodes, edges = trace(root)
for n in nodes:
uid = str(id(n))
# Create the 3-field rectangle
var_name = n.name if n.name else ''
label = f"{{ {var_name} | data={n.data:.4f} | grad={n.grad:.4f} }}"
dot.node(name=uid, label=label, shape='record')
# If there's an operation, create a circle for it
if n._op:
op_uid = uid + "_op"
dot.node(name=op_uid, label=n._op, shape='circle')
# Connect operation circle to this value rectangle
dot.edge(op_uid, uid)
# Connect operands (children) to the operation circle
for child in n._prev:
dot.edge(str(id(child)), op_uid)
return dot
3. Make the graph
# Inputs
a = Value(0.5001, name='a')
b = Value(0.71, name='b')
# Compute intermediates
t1 = a * b
t1.name = 't1'
t2 = t1 + b
t2.name = 't2'
c = t2 + a
c.name = 'c'
d = c.tanh()
d.name = 'd'
# Forward pass
print("Forward pass:")
print("a:", a.data)
print("b:", b.data)
print("c:", c.data)
print("d:", d.data)
# Backward pass
d.backward()
print("\nBackward pass (gradients):")
print("a.grad:", a.grad)
print("b.grad:", b.grad)
print("c.grad:", c.grad)
print("d.grad:", d.grad)
# Draw graph
draw_dot(d)
Result
#Forward pass:
#a: 0.5001
#b: 0.71
#c: 1.5651709999999999
#d: 0.9162542319535778
#Backward pass (gradients):
#a.grad: 0.27441769195044236
#b.grad: 0.24073332145898163
#c.grad: 0.16047818242715928
#d.grad: 1.0

Content: Neuron
Neuron(in computer) is a learnable unit. And as we said, to build a capable neuron, we need to activate it with a non-linearity such as tanh.
$$ y = \tanh(w_1 x_1 + w_2 x_2 + \cdots + w_n x_n + b) $$
Takes some inputs ($x_1$, $x_2$, …, $x_n$).
Multiplies each by a weight ($w_1$, $w_2$, …, $w_n$), which is learnable.
Adds a bias $b$ (also learnable).
Applies a non-linearity (like tanh) to produce output $y$.
Example
x1 = Value(0.5, name='x1')
x2 = Value(0.7, name='x2')
# Weights
w1 = Value(random.uniform(-1, 1), name='w1')
w2 = Value(random.uniform(-1, 1), name='w2')
b = Value(random.uniform(-1, 1), name='b') # bias
x1w1 = x1 * w1
x1w1.name = 'x1*w1'
x2w2 = x2 * w2
x2w2.name = 'x2*w2'
x1w1_x2w2 = x1w1 + x2w2
x1w1_x2w2.name = 'x1*w1 + x2*w2'
x1w1_x2w2_b = x1w1_x2w2 + b
x1w1_x2w2_b.name = 'x1*w1 + x2*w2 + b'
out = x1w1_x2w2_b.tanh()
out.name = 'tanh(x1*w1 + x2*w2 + b)'
print("Forward pass:")
for v in [x1, x2, w1, w2, b, x1w1, x2w2, x1w1_x2w2, x1w1_x2w2_b, out]:
print(f"{v.name}: {v.data:.4f}")
out.backward()
print("\nBackward pass (gradients):")
for v in [x1, x2, w1, w2, b, x1w1, x2w2, x1w1_x2w2, x1w1_x2w2_b, out]:
print(f"{v.name}.grad: {v.grad:.4f}")
draw_dot(out)
# Forward pass:
# x1: 0.5000
# x2: 0.7000
# w1: -0.8194
# w2: 0.9692
# b: 0.4034
# x1*w1: -0.4097
# x2*w2: 0.6784
# x1*w1 + x2*w2: 0.2687
# x1*w1 + x2*w2 + b: 0.6721
# tanh(x1*w1 + x2*w2 + b): 0.5864
# Backward pass (gradients):
# x1.grad: -0.5377
# x2.grad: 0.6359
# w1.grad: 0.3281
# w2.grad: 0.4593
# b.grad: 0.6562
# x1*w1.grad: 0.6562
# x2*w2.grad: 0.6562
# x1*w1 + x2*w2.grad: 0.6562
# x1*w1 + x2*w2 + b.grad: 0.6562
# tanh(x1*w1 + x2*w2 + b).grad: 1.0000

Content: PyTorch
Congrats! we built a neuron, by
1. Define Value objects to hold numbers and track their parents.
2. Compute gradients manually with backward() using the chain rule.
You can access the code here: https://github.com/auroramonet/memo/blob/main/codes/micrograd_1.ipynb
Let’s rewrite in PyTorch, a standard Python library for machine learning, which can create an autograd, by using Tensors (multi-dimensional array, similar to matrix)
Tensors can store numbers (inputs, outputs, weights, bias), so autograd (Automatic differentiation engine) can perform operations on them such as computing gradients, graphs.
Pytorch has more features:
Neural network modules: Predefined layers (like Linear, Conv2d) to easily build networks.
Optimizers: Prebuilt algorithms like SGD or Adam to update weights automatically.
GPU support: Tensors and computations can run on GPU for fast training.
Let’s begin
Note: Python uses float64 datatype (double precision) for floats, but PyTorch uses float32 (single precision), so we convert by .double()
pip install torch
import torch
torch.tensor([2.0]).double()
Note: Tensor doesn’t automatically store gradients of leaf nodes, to save memory and be efficient, while we can explicitly say to store which gradients for our purpose.
x1 = torch.tensor([0.5000]).double()
x2 = torch.tensor([0.7000]).double()
w1 = torch.tensor([0.0259]).double()
w2 = torch.tensor([0.1967]).double()
x1.requires_grad_(True)
x2.requires_grad_(True)
w1.requires_grad_(True)
w2.requires_grad_(True)
# Bias
b = torch.tensor([-0.7261]).double()
b.requires_grad_(True)
# Forward pass
x1w1 = x1 * w1
x2w2 = x2 * w2
sum_ = x1w1 + x2w2
sum_b = sum_ + b
out = torch.tanh(sum_b)
print(out.data.item())
out.backward()
print("x1.grad:", x1.grad.item())
print("x2.grad:", x2.grad.item())
print("w1.grad:", w1.grad.item())
print("w2.grad:", w2.grad.item())
print("b.grad:", b.grad.item())
# -0.5193578553128438
# x1.grad: 0.0189139266452323
# x2.grad: 0.14364360605503948
# w1.grad: 0.3651337090624216
# w2.grad: 0.5111871839819242
# b.grad: 0.7302674055099487
Content: Neuron in PyTorch
Watch this video first, it shows how a neural network works,
nn is a guessing machine! You feed it with input and output, then it tries to guess the way it can reach from the input to the output, by using layers of neurons, it does this by repeating the process, and calculating the loss to learn the path with the optimum results (lower loss) by
$$ \theta \leftarrow \theta - \eta \cdot \frac{\partial L}{\partial \theta} $$
$$ \theta_{n+1} = \theta_n - \eta \cdot \frac{\partial L}{\partial \theta} $$
$$ \text{w.data} -= \text{lr} \cdot \text{w.grad} $$
θ (theta)
A parameter
A number the model can change
e.g. a weight a bias
← (left arrow)
Means “update / assign”
Not an equality
Read as:
“Replace θ with the value on the right”
− (minus sign)
Means move in the opposite direction
Used because we want to reduce the loss
η (eta)
The learning rate
A small positive number
Controls how big the step is
Q Why do we need more than 1 neuron?
A Because each Neuron can only guess a formula, a simple shape (e.g. a line, a curve)
neuron:
$$ \text{neuron}(x) = \phi\left(\sum_{i} w_i x_i + b\right) $$
Where:
$x_i$ → inputs
$w_i$ → weights
$b$ → bias
$\phi$ → activation function (tanh, ReLU, etc.)
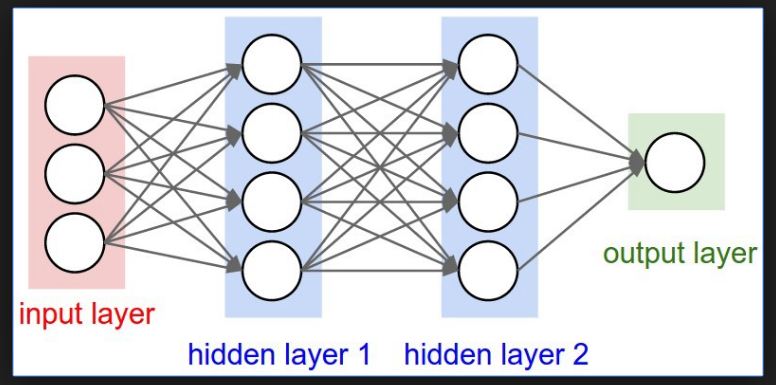
in each layer:
all neurons have:
same formula
same activation function
same number of inputs
same code
But
they have different weights and biases
Bias shifts where the neuron activates.
Let’s make a neuron in PyTorch,
To be Continued in Epoch 3
Resources
Micrograd - A Tiny Autograd Engine
A tiny scalar-valued autograd engine and a neural net library on top of it with PyTorch-like API, created by Andrej Karpathy.